検索エンジンがMTの検索結果ページで出力される、検索結果フィードをクロールしていたようです。その際にMTのシステムログに記録されてしまうのでちょっと対策してみました
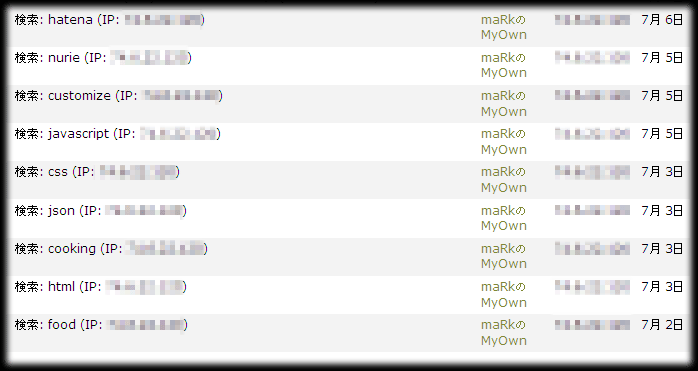
Movable Typeのシステムログをみたところ、検索のところにいくつか同一IPのものが並んでいました。そこまでは、よくあることなんですが。
{kind=link}
上のキャプチャ画像のアクセスはIPを調べた結果(というよりは、サーバの生ログからたどったのが実際なんですけど)、Yahoo!の検索ロボットであるということがわかりました。
MTのシステムログでは、「検索」という文字があるだけで実際のページのURIが示されていないものですから、実際の検索結果のページがタグ検索なのか、キーワード検索かといった区別が見た感じではわかりにくいです。そこで、サーバのログを使いまして同じIPのアクセスを調べたわけです
結果として、Yahoo!によるもので、URIは例えばpluginというタグをつけたページの検索結果ページで出力されているような場合、
/mt/mt-search.cgi?tag=plugin&Template=feed&IncludeBlogs=1
といったページをクロールしていたもようです。どのようなページかというと、タグ検索の結果をフィードで出力するページです。タグ検索結果のページで、link要素に記述されているURIです。
さて、検索ロボットのアクセスが毎回システムログにあがるのは、ちょっとうっとうしい感じ。なのでこの際、MTの検索結果ページそのものが検索エンジンに登録されないように調整してみることにしました。
robots.txtに以下のような記述でちょっと様子見ということにしています。
User-agent: Slurp Disallow: /*mt-search.cgi
[追記 2008/07/30] msnbot-mediaも巡回するっぽいです。
[28/Jul/2008:00:13:50 +0900] "GET /mt/mt-search.cgi?tag=driver&Template=feed& IncludeBlogs=1 HTTP/1.0" 200 1958 "-" "msnbot-media/1.0 (+http://search.msn.com /msnbot.htm)"